


6 Cache Strategies to Save Your Database's Performance
When a post goes viral with millions of views and reactions, all those reads and writes hit the database directly. That can totally overwhelm the database…

So, you're wondering how to make your application faster and give your database a bit of a break? Using a cache with a suitable strategy is one way to do that.

Let’s look at a social media example.
When a post goes viral, racking up millions of views and reactions, all those database reads and writes happen directly and can really slow things down. Multiply that by numerous viral posts, and you’re talking about billions of operations bogging down your database.
“What exactly does ‘cache population’ mean?”
Cache population strategies typically refer to how your application, database, and cache work together.
Now, it’s worth noting that many databases, like PostgreSQL with its Shared Buffer cache, or MongoDB with its WiredTiger internal cache and filesystem cache, do offer some built-in caching solutions.
Let’s break down these caching strategies into two main categories:
For reading data: cache-aside, read through, refresh ahead.
For writing: write through, write behind, write around.
1. Cache-aside (READ) or Lazy Loading
Also called lazy loading, Cache-aside is the most straightforward caching method you could consider. It works best for apps where most of the operations are reads, although it’s not exactly the top choice for scalability.
How it works?
The mechanics are straightforward:
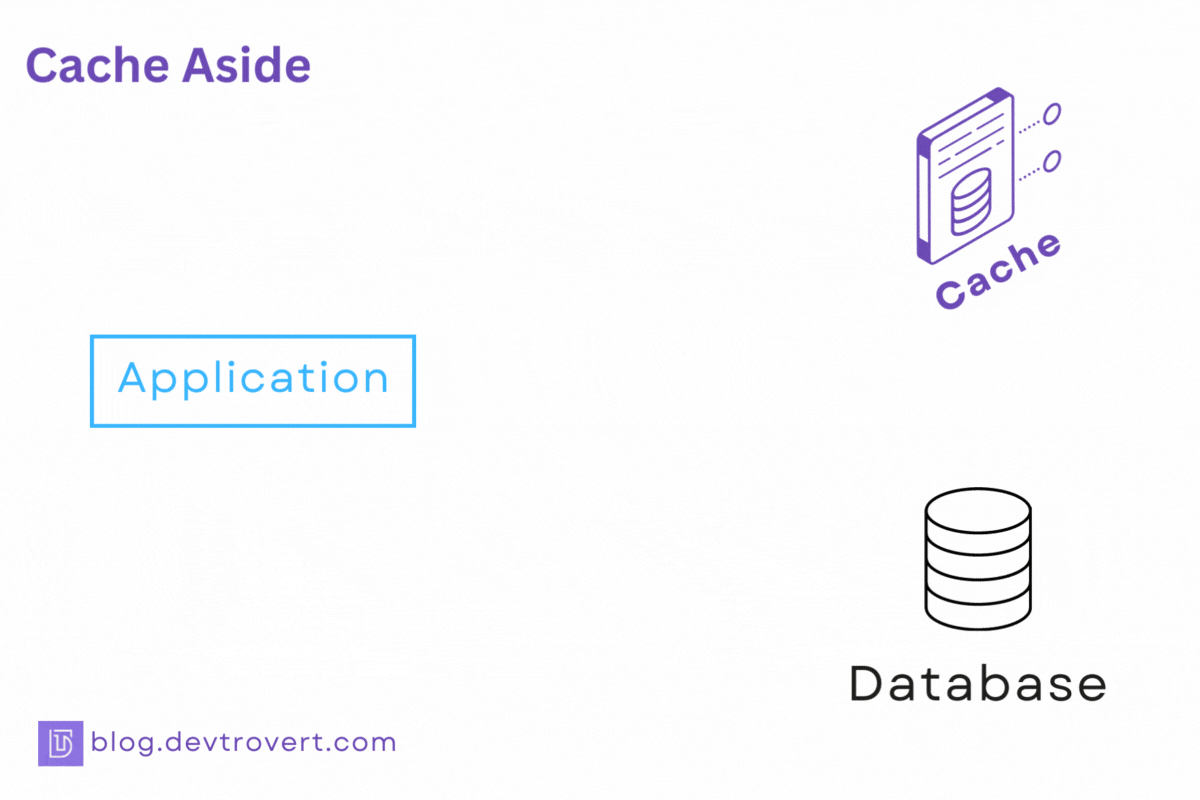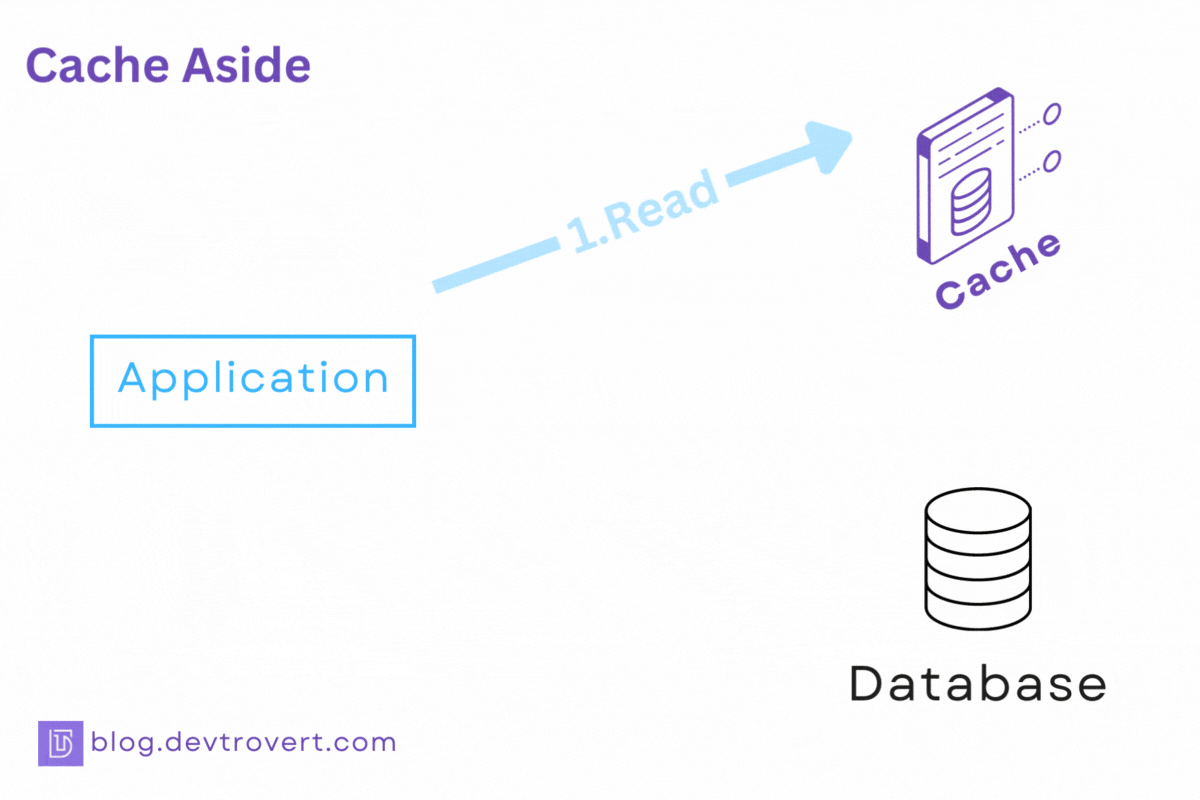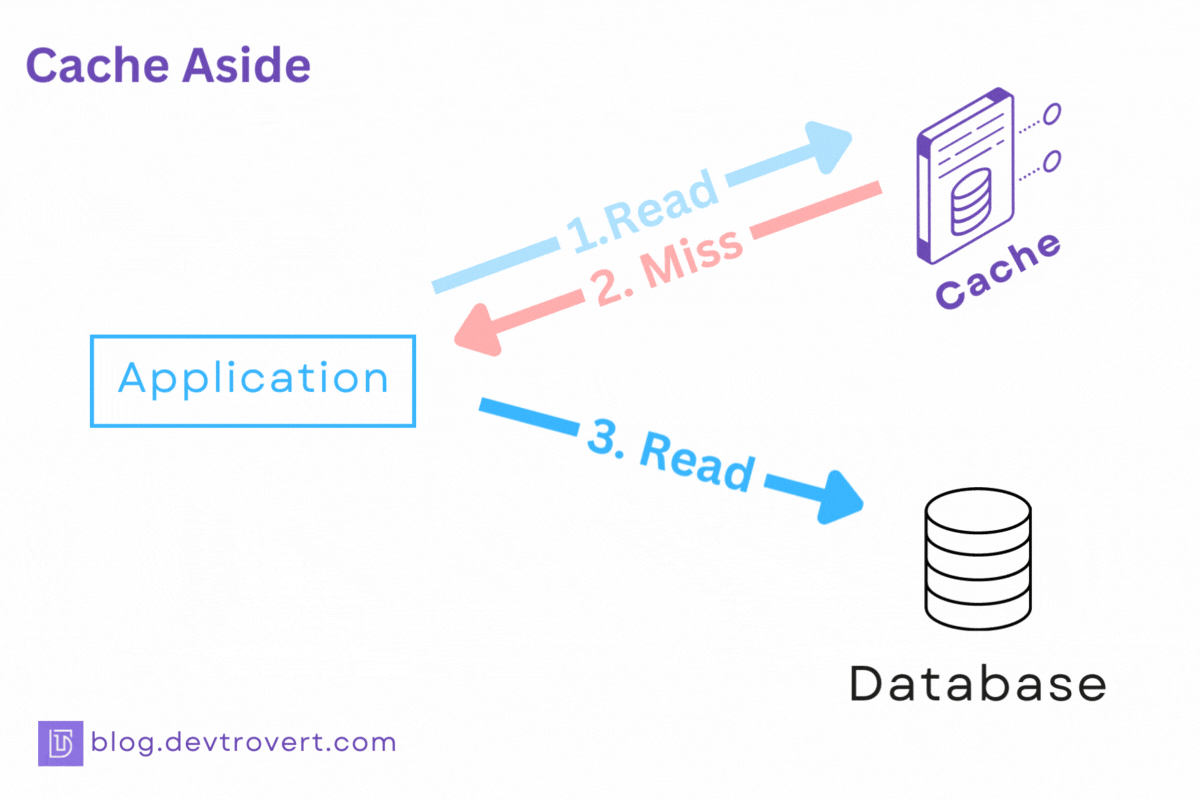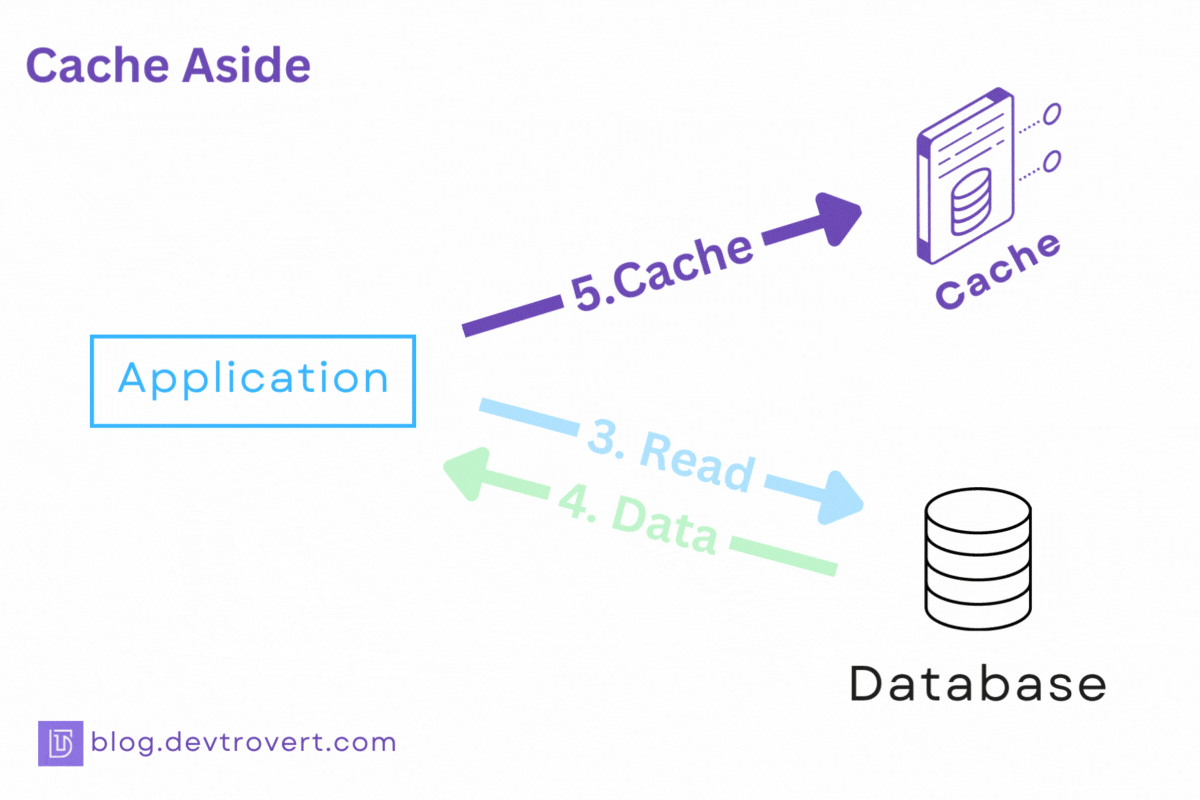
If a user’s requested data is in the cache, it gets sent back right away.
If not, we fetch it from the database, stash it in the cache, and then return it to the user.
Pros
Only needed data is cached: you only cache what people are asking for, so you know your cache is full of stuff users actually want.
Flexible customization, so you’re not limited to caching a single document but you can cache a bundle of multiple items for a specific query.
Database as backup, If anything goes wrong with the cache, your database is still there as a dependable backup.
Cons
Cache miss impact, a cache miss can slow down the request time, and there’s a risk of something known as a cache poisoning attack (I’ll explain later).
Additional code paths to manage: you’ll have to look after several things like pulling data from the cache, getting it from the database if it’s not in the cache, and then updating the cache, not to mention error handling.
Consistency can be tricky: determining if your cache is up-to-date or outdated can be a complex task.
Concurrent reads during cache update, there are moments when several reads might be hitting the database while you’re still filling the cache with new data
2. Read through (READ)
In this strategy, you let the cache library or service handle the data fetching and cache populating.
This way, your code only needs to call the repository (which is a mix of cache and database), without sweating the small stuff about how it all works.
With write operations, these go straight to the database. Whether or not to populate these changes in the cache is up to you. (I will talk about this when we come to the Write strategy)
How it works?
When your app asks the cache provider for a piece of data A, if it’s there, the service return it immediately.
If A isn’t in the cache yet, the service checks the database.
Once found, it saves A in the cache and hands it back to your app.

Pros
Simplified code handling, the cache service takes on the burden of managing both the database and the cache, so your app code stays lean.
Better consistency, since all read and write requests pass through the cache, it becomes simpler to keep your data uniform across both cache and database.
Prevents concurrent database reads: all data requests are routed through the cache, reducing the chance of simultaneous database reads with lock.
Cons
Need a learning curve: setting up this system from scratch has its own learning curve. It’s generally easier to rely on an established cache service or library.
Database specificity: if you’ve configured your cache to work with a particular database like MongoDB, ScyllaDB, then pivoting to a different database in the future could be a bit of a headache.
Less room for customization: Using a ready solution could mean you have to adapt to its rules.
For example, the duration data is stored (known as TTL) might not be flexible enough, some data might need to be stored for a month, while some for just a minute.
Limited data model flexibility, you might find yourself restricted to their data model, even when you’d prefer to use a different one for certain queries.
3. Refresh Ahead (READ)
What happens when you’ve got a trending post read by millions, and the cache expiration time for that post is fast approaching?
The Refresh-Ahead strategy aims to solve this problem by automatically renewing the cache’s time-to-live (TTL) for that particular post if it’s still being read close to its expiration time.
Before diving into the mechanics, it’s worth noting there’s a key variable in this strategy called the “Refresh-ahead factor”.
Say you set this factor at 0.5 and assign a 60-second TTL to item A. What happens is, the cache provider springs into action with an asynchronous refresh if item A is accessed when its TTL is already half spent.
How it works (using a Refresh-Ahead factor of 0.5)
The caching mechanism gives data item A a TTL of 60 seconds.
If someone accesses that item when the TTL is still at 31 seconds, no changes are made.
However, if that item is accessed when its TTL drops to 29 seconds, cache will still return that item, but also the cache provider asynchronously reaches out to the database for a TTL refresh.
Once completed, item A’s TTL is reset to a full 60 seconds.
Pros
Avoid cache miss delays, by refreshing popular items before they expire, you cut down on cache misses and the latency they can cause.
Cons
Complex refresh criteria, which items should get their TTL refreshed isn’t straightforward; it requires a thoughtful balance of your specific needs.
Unneeded caching of less popular items, so if an item isn’t truly trending but just receives occasional reads, the cache may still renew its TTL.
4. Write Through (WRITE)
Remember when I discussed how write operations work in the read-through scenario?
In Write-Through, data is first written directly into the cache and then immediately synchronized with the database.
How it works?
The application sends a write command to the cache.
The cache then updates the data based on that write command.
Finally, that updated data is sent over to the database.

Pros
Consistency is key, Because the cache and database sync in a single operation, your data stays consistent.
Quick subsequent reads, If you’ve just written new data, the next time you read it will be fast because the cache has the freshest data available.
This strategy combines nicely with a read-through approach for caching.
Cons
Slower writes, since writing happens both in the cache and the database at the same time, it can slow down the write operation.
Not atomic, this becomes an issue when you’re updating a single resource with parallel writes.
Inefficient use of cache resources, the cache ends up storing data that’s written more often than it’s actually read, which isn’t super efficient.
5. Write Behind (WRITE) or Write Back
Just like in Write Through, the first step is to write data to the cache. However, we delay a bit when it comes to updating the database. Instead of syncing right away, we take an asynchronous approach and write to the database after a configurable delay.
So imagine, you have a post going viral and reactions are skyrocketing into the millions. Directly logging all those reactions into the database would be overwhelming, right? that’d put too much stress on it.
So we set a limit, let’s say, 1000 reactions before committing the data to the database.
“What happens if a post is just shy of the 1000-reaction mark? Like, it gets stuck at 999?”
Good question.
Our strategy has a workaround for that, we can choose to write the data based on either the number of reactions or after a certain period, say, a second has passed.
We could even use a combination of both, so whichever condition is met first triggers the write.
How it works?
The application sends a write operation to the cache.
The cache writes to the data on the cache, returning the new data immediately.
If the flush conditions are satisfied, the cache will write to the database asynchronously.

Pros
Optimized database load: by deferring database writes and using batch updates, you avoid overloading it, this is particularly useful for those viral posts with tons of reactions.
Fast response: since the cache is the first to get updated, your application will receive a quick response.
Flexibility: you can set different triggers for flushing; it could be based on a number count or a time limit.
Cons
Potential data loss: if the cache crashes before an asynchronous write to the database is completed, that data is gone.
Complexity in management: you’re adding another layer to your workflow by having to manage asynchronous writes, and perhaps even a fallback system.
Stale data risk: the database isn’t getting immediate updates, so if you bypass the cache, you risk encountering outdated data.
Requires careful tuning: you’ll have to watch and fine-tune your settings for flush conditions and time delays.
Inefficient use of cache resources like Write-through.
6. Write Around (WRITE)
Write Through and Write Behind have insufficient cache usage, since you’re dealing with data that isn’t frequently accessed but is updated regularly right?
In such a case, you might not want to flood your cache with this type of data, only to push out more frequently accessed items.
How it works?
The application performs a write operation, but it goes directly to the database.
The cache isn’t updated at this point.
When a read request comes in for that data, only then is it loaded into the cache

Pros:
Efficient cache usage: the cache only stores data that is read frequently, avoiding unnecessary use of cache resources.
Suits infrequently accessed data: Ideal for data that is written often but not read as much.
Cons:
Delay in subsequent reads: the first read following a write operation will be slower since the data has to be pulled into the cache.
Complexity: you’ll still need to manage what gets into the cache and what doesn’t, making cache policies a bit complicated.
Un-optimizing write: since the write goes directly to the database, there’s less complexity in handling asynchronous writes or batching.
Risk of stale data: if you read from the cache right after a write, you may get old data unless the cache is refreshed.
Before you dive into crafting your own cache strategy, first ask yourself if you truly need the performance boost. Sometimes, adding a caching layer can complicate things without delivering any real benefits.
And don’t forget, your database might already have built-in caching features, so look into that as well.
nice post!
The way you described everything was well organized and clear! Very helpful and thank you for writing this :)