


Go EP9: How to Gracefully Shut Down Your Application
When we talk about gracefully shutting down an application, there are a few key guarantees we aim to achieve:


If you haven’t read the last week, then here is the recap:
Take 1: Using unexported empty struct as context key
Take 2: Make your errors clear with
fmt.Errorf, don’t just leave them bare.Take 3: Avoid
deferin loops, or your memory might blow up.Take 4: Handle errors while using defer to prevent silent failures

This week’s topics:
Take 1: Sort your fields in your struct from largest to smallest.
Take 2: Single touch error handling, less noise.
Take 3: Gracefully shut down your application
Take 1: Sort your fields in your struct from largest to smallest.
I did a story about field padding and alignment before, but this time it comes as a tip.

The order of fields in a struct really does affect its size, which means we can use this to optimize memory usage, right?
Let’s see an example (ignore the comments of each field for now):

The StructA uses 32 bytes, whereas OptimizedStructA requires only 16 bytes. To understand why two structs with the same fields differ in size, let’s explore alignment and padding of field:
Alignment: Data types have specific alignment requirements based on their size. For example, an int32 might require alignment on a 4-byte boundary, meaning its starting memory address should be divisible by 4.
Padding: To satisfy alignment requirements, compilers may insert unused space (padding) between struct fields.
Let’s look at StructA’s internal representation, which is 8x4 bytes, and try to explain with the above idea: Here is the explanation of each field of StructA:
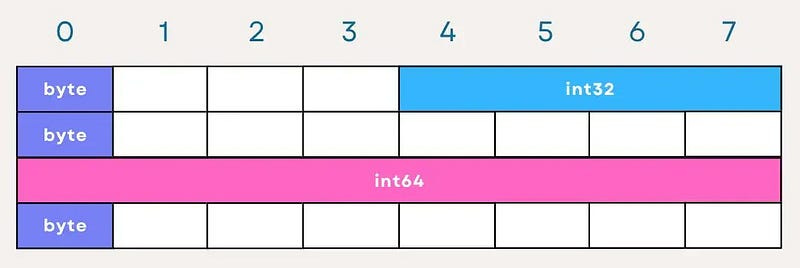
A (byte): Occupies 1 byte, but since the next field B requires 4-byte alignment, there are 3 bytes of padding after A to align B properly.
B (int32): 4 bytes, no padding needed after since the next field C is a byte.
C (byte): Again, takes 1 byte, but to align D (which needs 8-byte alignment), 7 bytes of padding are added after C.
D (int64): 8 bytes and fully utilizing its slot.
E (byte): The final byte, simply follows “D” in memory, and depending on the context, it might lead to additional padding at the end of the struct to align the whole struct’s size to a boundary.
Now, with OptimizedStructA:
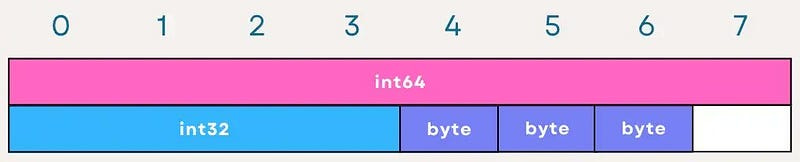
D (int64): Placed first to utilize its 8-byte alignment requirement without preceding padding.
B (int32): Follows, aligning on a 4-byte boundary naturally after D.
A, C, E (bytes): Grouped together afterward, since they are single-byte types, they don’t require additional padding between them.
By ordering fields from largest to smallest, we minimize the padding required, reducing the struct’s total size (and memory).
A tool like betteralign can detect inefficient alignments and may help in automatically reordering them for efficiency: https://github.com/dkorunic/betteralign.
It’s important to note that reordering for efficiency is not always applicable or necessary.
Keeping struct fields in an order that makes sense for how they’re used or how important they are can make the code easier to read and work with, even if it doesn’t use the least amount of memory.
Take 2: Single Touch Error Handling, Less Noise.
This is something I did before, assume we have a function A calling B, and both handle errors like this:

When B encounters an error, it logs the issue and passes the error up to A.
A, upon receiving this error, does the same: logs it and may even pass it further up the chain.
Why is this a problem?
This might seem like thorough error handling because we can trace back from log to log, but it’s actually just noise.
Here are some problems:
Duplicate logs: This creates noise in your log files, making it harder to diagnose issues because the same error is recorded multiple times.
Complex error handling: It complicates the error handling logic.
Potential for other errors: Handling errors multiple times means more code, more code means more potential for bugs.
The single-touch-on-error tip suggests that for each error encountered, there should be a single, well-defined point in the code to deal with the error.
With one error, consider handling it only once, but how do you do that efficiently?
Better Solution
A better approach would be to decide whether to handle the error or return it for handling at a higher level (but not both simultaneously).

Let the caller decide how to handle it, whether to log it, panic, wrap it with additional context, or take some corrective action.
Take 3: Gracefully Shut Down Your Application
When we talk about gracefully shutting down an application, there are a few key guarantees we aim to achieve:
No new requests: The server stops accepting new requests.
Completion of ongoing tasks: Waits for currently processing tasks to reach a logical stopping point.
Resource cleanup: We release resources such as database connections, open files, network connections, etc.
There are some different implementations out there, but I try to give the shortest way for simplicity:

First, we create a (main) context that is cancelled when an interrupt signal (Ctrl+C) or a SIGTERM is received.
Then we make 2 goroutines, both coordinated by errgroup (if you don’t know what it is, consider reading from https://blog.devtrovert.com/p/go-errgroup-you-havent-used-goroutines…):
The first one is straightforward, launching the server but remember, ListenAndServe always returns a non-nil error.
The second is interesting, it’s the place we can put our graceful cleanup. This goroutine waits for gCtx.Done() to close, which is propagated from our main ctx.
If our service is running on Kubernetes, consider not terminating new requests immediately after SIGTERM.
Your application must not terminate instantly, but rather complete all active requests and continue to listen for incoming connections that arrive after the Pod shutdown begins. It may take a bit for Kubernetes to update all kube-proxies and load balancers.
This is the simplified version, you may consider adding a timeout to the server’s configuration, checking if the error is closed, adding a timeout to the shutdown,…