


Pointers in Go: To Use or Not To Use? My Personal Guide
With pointers, you’ll be able to pass references to values instead of copying them, !(saving memory and improving performance)


In using pointers, you can alter values by reference, avoiding the need to copy them, this not only simplifies your code but also makes modifications more straightforward.
My goal here is to give you a thorough understanding of how to use pointers, from the basics to the more complex techniques.
And we’ll solve the golden question: “Should I use a pointer in this situation?”
1. Quick look about pointer (Optional)
If you’re already familiar with the use of pointers in Go, feel free to skip this section.
Pointer
Let’s start by looking at a very simple example:
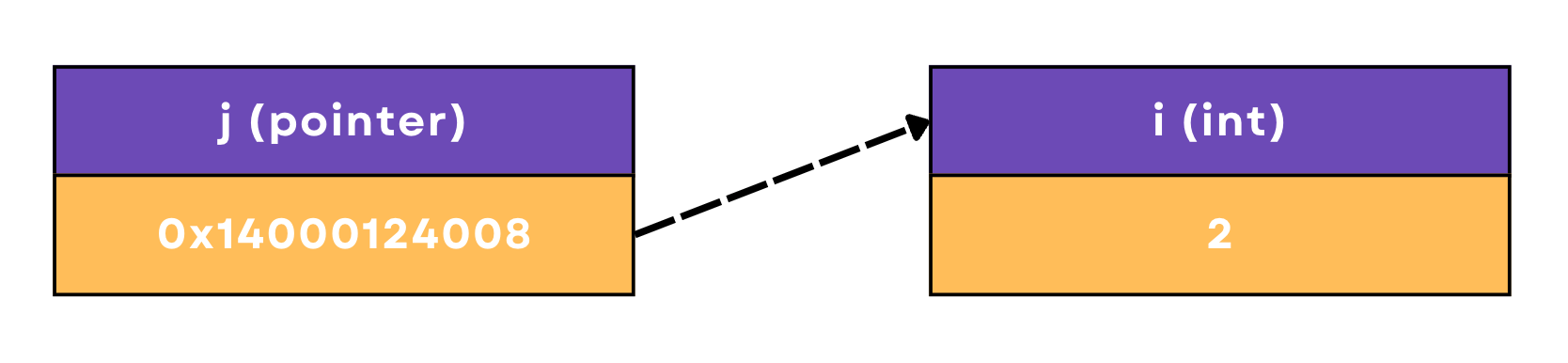
func main() {
var i int = 2
j := &i
fmt.Println("i address:", j) // i address: 0x14000124008
fmt.Println("i value:", *j) // 1 value: 2
}Here, I first declare an integer variable i and give it a value of 2. Then I create a pointer j using the & symbol and retrieve the value that j points to using the * symbol.
“Why is the memory address of ‘i’ different on my end? What’s going on?”
The output can change with each program run due to how memory is allocated. The precise location where a variable is stored can shift because the operating system has different memory allocation methods for each run.
Another application for pointers is when you’re passing them into functions:
// pointer as argument
func add1Ptr(i *int) {
*i = *i + 1
}
func add1(i int) {
i = i + 1
}
func main() {
var i int = 2
var j int = 2
add1(i)
add1Ptr(&j)
fmt.Println("i:", i) // i: 2
fmt.Println("j:", j) // j: 3
}In this scenario, the i value passed to the incrementWithoutPointer() function stays the same because Go passes all arguments by value.
But by sending a pointer, which indicates a specific memory location, you can effectively alter the value at that location.
Method pointer receiver
If you’re familiar with Go, you might know that function receivers operate much like methods in certain object-oriented languages.
To make this clearer, let’s walk through an example:
type Number struct {
i int
}
func (n Number) add1() {
n.i++
}
func (n *Number) add1Ptr() {
n.i++
}Here, we’ve defined a struct called Number, which holds an integer variable, we also define two methods, incrementMethod and incrementPointerMethod, associated with this Number struct.
If you’ve been paying attention to the previous example, you likely anticipate what comes next.
func main() {
n := Number{i: 2}
n.add1()
fmt.Println(n.i) // 2
n.add1Ptr()
fmt.Println(n.i) // 3
}In essence, this is not much different from our previous example.
2. A bug with using a pointer value in a slice with ‘for range’
I’ve run into some pitfalls when using pointers with ‘for range’ loops, particularly when employing &v. I touched on this matter in a prior article called Go For-Range Slice Bug: Lessons Learned

To sum it up, if you’re thinking about using &v within a ‘for-range’ loop, I’d caution against it unless you really know what you’re doing.
It’s a quick way to run into unexpected outcomes or weird issues.
3. Misunderstanding Pass-by-Value
I’ve noticed that many developers, including my past self, try to alter the pointer passed into a function like this, making debugging a real challenge:
// example 1
func modifyVer1(n *int) {
result := 0
// ...
n = &result
}
// example 2
func (n *Number) modifyVer2() {
result := Number{i: 0}
// ...
n = &result
}In truth, doing it this way only changes a copy of the pointer, not the actual pointer itself.
Let’s revisit our prior example to clarify this point, I’m including it here for easy reference if you skipped that part:
// pointer as argument
func add1Ptr(n *int) {
*n = *n + 1
}
func add1(n int) {
n = n + 1
}
func main() {
var i int = 2
var j int = 2
add1(i)
add1Ptr(&j)
fmt.Println("i:", i) // i: 2
fmt.Println("j:", j) // j: 3
}What’s your take on the (n *int) argument in the add1Ptr function, compared to the pointer &j?
These are two separate variables. When we pass &j to add1Ptr, we’re basically making a new pointer that contains the same memory address as the original:

“How did you come to that conclusion?”
Continuing with our discussion, I’ve decided to streamline the example by removing the add1 function and the i variable.
We’ll instead focus on printing the addresses of n and j for a clearer understanding:
// pointer as argument
func add1Ptr(n *int) {
*n = *n + 1
fmt.Println("n:", n)
fmt.Println("&n:", &n)
}
func main() {
var j int = 2
var jPtr = &j
add1Ptr(jPtr)
fmt.Println("jPtr:", jPtr)
fmt.Println("&(&j):", &jPtr)
}n: 0x1400001a0b0 // the value which n is holding
&n: 0x1400000e030 // the memory address of n
jPtr: 0x1400001a0b0 // the value which jPtr or &j is holding
&(&j): 0x1400000e028 // the memory address of &jAs you can see, here, the memory addresses for &n and &jPtr are different.
The key takeaway here is that while these are distinct variables, they do hold the same memory address, which is where j resides in the main function.
4. How can I determine when to use pointers?
If you’re wondering when to bring pointers into your code, you’re asking the right questions. “Should I pass a pointer as an argument?” or “Is it better to return a pointer to a struct, rather than the struct itself?” are good starting points.
Pointers can come in handy, but there’s a caveat: once they’re passed around your code, they can be changed anywhere.
This is why setting guidelines for using pointers and other elements like maps and slices is so important.
0. Mutability
When we think about using pointers, mutability often comes up first right? That’s because pointers offer the only way to change a variable after you’ve sent it into a function.
Another option is to use methods that have a pointer receiver, which allows us to modify a variable’s inner details.
Here’s an example to illustrate
type Person struct {
Name string
Age int
}
func (p *Person) AddNewYear() {
p.Age++
}We’ve talked about this before, so let’s move on.
1. Large struct? short life?
I’ve learned from online resources like StackOverflow, Google,… that using pointers for large structs can help with performance. Why? Because you avoid the slowdown that comes with copying large structs by value.
But then, what’s considered ‘large’?
A nod to @philpearl for his eye-opening post about “Bad Go: pointer returns”.
He tested how returning a struct stacks up against a pointer in terms of performance. (Un)Surprisingly, only really big structs showed any slow-down.
For me, the decision to use a pointer isn’t solely about the struct’s size, it’s also about how long I plan to keep that pointer around, so if I opt for a pointer, that variable needs to serve a useful role for its entire lifespan.
2. Encoding and decoding with omitempty
When working with marshaling or unmarshaling JSON, you’ll find that using omitempty on a nested struct isn’t possible, which can be a bit annoying. If you’re new to omitempty, I recommend checking out this post: ‘Go JSON: ALL You Need To Use encoding/json Effectively’

So what’s the solution? To skip an empty field in a nested struct, you can use a nil pointer:
type Person struct {
Name string
}
type Omit struct {
ShowField Person `json:"showField,omitempty"` // <-- show even Person is default struct
HiddenField *Person `json:"hiddenField,omitempty"`
}
func main() {
omit := Omit{}
bytes, _ := json.Marshal(omit)
fmt.Println(string(bytes))
}
// {"showField":{"Name":""}}Yet another reason to think about using pointers is when you want to know if a struct has been populated or is empty.
In situations like these, pointers can be really helpful for making decisions.
3. Prefer using value
The CodeReviewComments suggest: ‘When in doubt, use a pointer receiver’.
But personally, I typically opt for pointer receivers only if I need to change the internal state of a struct and this serves as a signal to other developers that this particular function alters the state.
Pointer can be passed around and modified without much thought, and they often lag behind structs in terms of performance.