


What is unsafe.Pointer, or uintptr?
unsafe.Pointer, uintptr seem like total black magic to many Go developers. And admittedly, they are seriously magical, let me show you an example…


unsafe.Pointer, uintptr seem like total black magic to many Go developers. We often just use them as special spells for packages without really understanding how they work under the hood.
And admittedly, they are seriously magical, let me show you an example of how I can use unsafe pointers to rejuvenate a person.
type Person struct {
Name string
age int
}
func main() {
person := Person{Name: "John", age: 30}
// Cast name to unsafe pointer
namePtr := unsafe.Pointer(&person.Name)
nameSize := unsafe.Sizeof(person.Name)
p := (*int)(unsafe.Add(namePtr, nameSize))
*p = 10
fmt.Println(person) // {John 10}
}By doing some unsafe pointer math, I can modify the private age field through the public Name field. This approach is totally unintuitive, but it works, changing John’s age from 30 to 10.
Understanding how to safely leverage unsafe pointers enables building powerful functionality.
1. What really is unsafe.Pointer?
To get a start, let’s examine its definition in the code:
type Pointer *ArbitraryTypeUnlike a *int, which can only point to an int, or a *bool, which is restricted to bool values, unsafe.Pointer has the liberty to point to any arbitrary type, sweet flexibility right?
unsafe.Pointer is a special kind of pointer that turns off the usual safety rules. When you use it, you're telling the Go compiler: “I know what I'm doing, so trust me”. Be careful, because you're going around the normal safety checks. I'll talk more about this soon.
Now, here’s an important point: unsafe.Pointer can be converted to any type of pointer. For example, you can change a *int pointer to an unsafe.Pointer, and then change that unsafe.Pointer to a *float64 pointer without any issues.
var a int64 = 10
aPtr := unsafe.Pointer(&a)
b := (*float64)(aPtr)“But what’s the value of
b? Is it 10 but as a floating-point number?"
No, it’s not.
int64 and float64 both use 64 bits, but they store data differently. int64 stores numbers as integers, and float64 stores numbers in a floating-point format.
If you print b, you'll get a value like 5e-323.
Now that we’ve covered unsafe.Pointer, let's talk about another type of pointer: uintptr.
What is uintptr?
A uintptr is basically an integer designed to hold a memory address. It's an unsigned integer that can act like a pointer. What does this mean in simpler terms?
In the world of computers, each memory location is identified by a number, and that's what uintptr holds, the number that points to a specific memory location.
Now, here comes the trap.
If you’re familiar with Go, you know it has a garbage collector that clears out memory not being used anymore. Specifically, it scans your code to find values that are no longer being referenced. This makes life easier because you don’t have to manually manage memory like you would in languages such as C.
var a int64 = 10
var aPtr = &aAs long as aPtr has the memory address of a, that section of memory will stay in use. This is because the Go garbage collector sees that this memory is still linked to your code, so it won't remove it.
But!
uintptr is a bit different, it's just a number that can hold a memory address. So unlike other pointers, it doesn't actually link to the memory in a way the garbage collector understands.
var a int64 = 10
aPtr := uintptr(unsafe.Pointer(&a))In this example, aPtr is a uintptr holding the memory address of a. But if all pointers that directly link to a disappear, the garbage collector gets confused. It won't realize that aPtr is supposed to be connected to a.
The result?
The garbage collector might just clear out the memory where a is stored. If that happens, aPtr becomes what's known as a "dangling pointer."
It would point to an area in memory that's been cleared and might be used for something else later. If you try using aPtr after this, the behavior of your program becomes unpredictable.
2. unsafe package
Beside unsafe.Pointer, this package provide us several functions provide low-level information, make us understand more about the internal structure of type.
unsafe.Alignof
The alignment is a concept which bring from the low-level programming, it returns the required alignment of a type and the layout of memory can affect the performance of our application.
For example, an int32 has an alignment of 4 bytes. The alignment of a struct depends on the field with the largest alignment:
type Person struct {
Name string
age int
}
func main() {
var i int32 = 1
var s [3]int8 = [3]int8{1, 2, 3}
var p Person = Person{"Bob", 20}
fmt.Println("aligno(int32) =", unsafe.Alignof(i))
fmt.Println("alignof([]int8) =", unsafe.Alignof(s))
fmt.Println("alignof(Person) =", unsafe.Alignof(p))
}
// aligno(int32) = 4
// alignof([3]int8) = 1
// alignof(Person) = 8I won’t dive too deep into alignment here, but it’s good to be aware of for performance.
“Where can I start to understand alignment?”
I’d recommend checking out this awesome talk What is Alignment? A Small Change for a Huge Impact. It covers how structs align fields in memory and how you can tweak alignment to optimize struct size, quite insightful stuff.

unsafe.Offsetof
unsafe.Offsetof basically returns the distance in bytes between the start of a struct and the start of a specific field. This is useful for understanding struct memory layouts.
In case that’s unclear, let’s walk through an example adapted from the Struct Optimization post:
// 32 bytes
type StructA struct {
A byte // 1-byte alignment
B int32 // 4-byte alignment
C byte // 1-byte alignment
D int64 // 8-byte alignment
E byte // 1-byte alignment
}Given the field alignments, StructA would be organized in memory something like this:
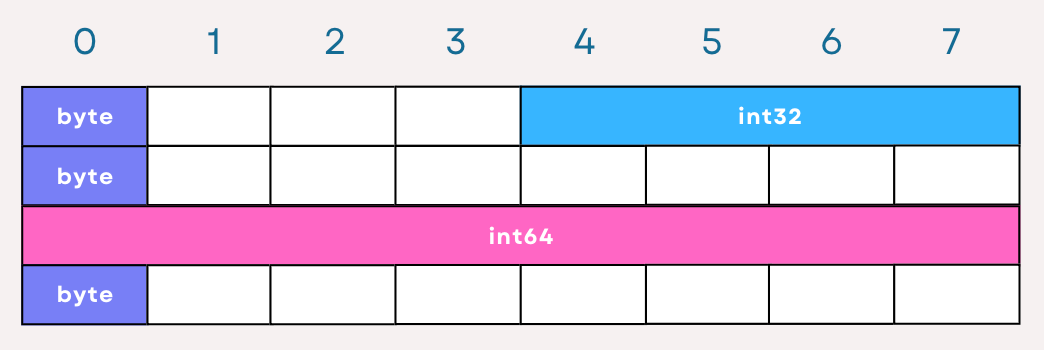
Now let’s use unsafe.Offsetof to confirm our visualization:
func main() {
a := StructA{}
fmt.Println("sizeof(A byte) =", unsafe.Offsetof(a.A))
fmt.Println("sizeof(B int32) =", unsafe.Offsetof(a.B))
fmt.Println("sizeof(C byte) =", unsafe.Offsetof(a.C))
fmt.Println("sizeof(D int64) =", unsafe.Offsetof(a.D))
fmt.Println("sizeof(E byte) =", unsafe.Offsetof(a.E))
}
// sizeof(A byte) = 0
// sizeof(B int32) = 4
// sizeof(C byte) = 8
// sizeof(D int64) = 16
// sizeof(E byte) = 24Knowing these byte offsets allows us to better understand the struct’s memory organization and do pointer arithmetic to access specific fields.
unsafe.Sizeof
The unsafe.Sizeof function returns the size in bytes needed to store some value in memory. It’s handy for seeing how much space a type takes up.
“I've tried both unsafe.Sizeof and unsafe.Alignof, and they both return the same value”
That’s mostly true, but not the full picture. For basic types like int or string, these values often do match. For example:
int: sizeof = 8 | alignof = 8
int32: sizeof = 4 | alignof = 4
string: sizeof = 16 | alignof = 8While unsafe.Sizeof tells you the total bytes a type occupies, unsafe.Alignof has a different role. It indicates the required spacing between elements of that type, depending on the CPU architecture.
var a complex128
fmt.Println("complex128: sizeof =", unsafe.Sizeof(a), "; alignof =", unsafe.Alignof(a))
// complex128: sizeof = 16 ; alignof = 8In the instance outlined, although a complex128 utilizes 16 bytes of memory, CPU efficiency is optimized when alignment occurs on 8-byte boundaries (given the 64-bit architecture of my system).
3. Use unsafe.Pointer Safely with These 6 Patterns
If you check out the Go documentation for the ‘unsafe’ package, you’ll find that the Go Team suggests 6 specific ways to use unsafe.Pointer.
The goal of these six methods is to use ‘unsafe’ pointers in the safest way possible. By sticking to these guidelines, you’re reducing the risks in an area that’s inherently tricky.
I noticed that most of the methods advise against storing uintptr in a variable, for the reasons we've already discussed (with the exceptions of pattern 1 and 6).
Pattern 1: Converting a T1 Pointer to a T2 Pointer
You might remember this from the example where I converted a pointer from *int64 to *float64. Here’s the code for a quick refresher:
var a int64 = 10
aPtr := unsafe.Pointer(&a)
b := (*float64)(aPtr)The important thing to note is that you should only do this kind of conversion if you’re 100% sure that the memory structures of T1 and T2 are compatible.
“Why should I use this pattern?”
A simple scenario where this comes in handy involves converting an array of one type to an array of another type. For example, let’s say we have this:
type MyInt int
func Print(arr []int) {
fmt.Println(arr)
}
x := []MyInt{1, 2, 3}If you try to use Print(x), you'll get a compile-time error because you can't use []MyInt as []int.
This is where the conversion pattern comes into play. You can convert MyInt to int because they both use the same memory structure:
y := *(*[]int)(unsafe.Pointer(&x))
Print(y) // [1, 2, 3]Remember, x and y are using the same memory, so changing one will affect the other.
Pattern 2: Turning Unsafe.Pointer to uintptr and Back, But Be Careful!
We don’t need to go into detail here because we already talked about the risks of using uintptr, remember?
So, if you want to play it safe, don’t change a uintptr back to an unsafe.Pointer. You can do it, but only in very specific situations. For example:
// GOOD: Changing to uintptr and immediately back to unsafe.Pointer.
newPtr := unsafe.Pointer(uintptr(ptr))
// BAD: Saving the uintptr value for later.
storedPtr := uintptr(ptr)
// Changing it back to unsafe.Pointer is risky.
newPtr := unsafe.Pointer(storedPtr) // Not safePattern 3: Switch from Unsafe.Pointer to uintptr for Arthimetic
If you remember the black magic part at the start of this article, this is the pattern we’re talking about. Instead of using the unsafe.Add function (introduced in Go 1.17), we’re using basic math to get the job done.
Here’s what this pattern looks like in practice:
type Person struct {
Name string
Age int
phone string
}
func main() {
p := Person{Name: "Tom", Age: 18, phone: "123456789"}
agePtr := unsafe.Pointer(uintptr(unsafe.Pointer(&p)) + unsafe.Offsetof(p.Age))
fmt.Println(*(*int)(agePtr)) // 18
}Let’s look back at the key line of code:
uintptr(unsafe.Pointer(&p)) + unsafe.Offsetof(p.Age)What we do here is briefly change the unsafe.Pointer to a uintptr, use some quick math to find where the Age field is located, and then change it back to an unsafe.Pointer.
But here’s what we don’t do:
pRawPtr := uintptr(unsafe.Pointer(&p))
agePtr := unsafe.Pointer(pRawPtr + unsafe.Offsetof(p.Age))Why?
Because storing a uintptr in a variable is risky business.
Pattern 4: Using uintptr with Syscalls
Having a function whose arguments are uintptr is generally something I consider bad practice. But Syscall is one of those special cases that require it.
So, how can we navigate this safely?
// GOOD
syscall.Syscall(SYS_READ, uintptr(fd), uintptr(unsafe.Pointer(p)), uintptr(n))
// BAD
u := uintptr(unsafe.Pointer(p))
syscall.Syscall(SYS_READ, uintptr(fd), u, uintptr(n))Pattern 5: uintptr returned from reflect.ValueOf(..).Pointer/UnsafeAddress
If you want to get the memory address, you can use the reflect package like this:
reflect.ValueOf(p).UnsafeAddr()
reflect.ValueOf(p).Pointer()However, both of these methods give you a uintptr, which can be risky. The guideline here is to not store the output of these methods, but to use them directly to sidestep the pitfalls of uintptr.
// GOOD
p := (*int)(unsafe.Pointer(reflect.ValueOf(new(int)).Pointer()))
// BAD
u := reflect.ValueOf(new(int)).Pointer()
p := (*int)(unsafe.Pointer(u))As of Go 1.19, you have a safer alternative: reflect.ValueOf(..).UnsafePointer().
Pattern 6: Convert from string or slice to reflect.StringHeader and reflect.SliceHeader
If you dive into how strings and slices work in Go, then you’ll find something interesting. The pointers of strings or slices don’t point directly to the memory of the array they represent but actually they point to a different structure known as a Header (StringHeader, SliceHeader).
type StringHeader struct {
Data uintptr
Len int
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}The Data field in StringHeader can trip you up.
It’s actually the pointer that points to the string’s bytes, while our string pointer just refers to this header. So, to get to the real data, we have to go through that.
I will demonstrate this with pattern 6, using a typical example: convert a string into a byte slice without allocating (thanks to the unsafe package)
To do this, we’ll use pattern 1, where we cast the *string as *T1 to an unsafe.Pointer and then to a *reflect.StringHeader as *T2.
str := "hello"
var b []byte
// Reinterpret the string's header as a slice header
strHeader := (*reflect.StringHeader)(unsafe.Pointer(&str))
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&b))
// Copy the data pointer and length from the string header to the slice header
sliceHeader.Data = strHeader.Data
sliceHeader.Len = strHeader.Len
sliceHeader.Cap = strHeader.Len
fmt.Println(b) // [104 101 108 108 111]
fmt.Println(string(b)) // helloNow b points directly to the raw bytes of the original string without any new allocation.